
| 7th Generation CPU Comparisons. |
|
|
| AMD Athlon | TransMeta Crusoe | Willamette |
The following information comes from various public presentations on the Athlon that have been given. One in particular is the "dinner with Dirk Meyer" audio session provided by Steve Porter/John Cholewa. I also did my own analysis on a real Athlon. I must also thank Lance Smith -- my inside man at AMD -- for invaluable assistance.
| The AMD Athlon Processor |
The Athlon, formerly known as the K7, is AMD's follow on to the AMD K6 microprocessor. Now I was already a fan of the K6 architecture, so I was expecting good things from the K7. I would say they have delivered.
On 08/09/99 a flurry of benchmarks disclosures and reviews accompanied AMD's official announcement of general availability of the Athlon processor. With only some inexplicable exceptions they all basically say the same thing: Athlon is simply faster than the Pentium !!!, at the same clock rate, and in absolute performance.
Shockingly, at the time of release, at the 650Mhz Athlon became the second highest clocked modern CPU available on the market -- beaten only by the Alpha 21264 at 667Mhz.
But enough of all the hype. Just how good is this architecture? The Athlon as far as I can tell is a cross between a K6, and an Alpha 21264. It has the cleanliness of the K6 architecture while having a no holds barred brute force set of functional units like the 21264.
AMD touts the Athlon as the first processor that can be considered 7th generation. Most of the features of the K7 are really just super beefed up features that exist in the K6 (and P6). But what differentiates it is its radically out of order floating point unit. Through a combination of 88 (!!) rename registers, with stack and dependency renaming on a fully superscalar FPU AMD has created, with the possible exception of the 21264, what is probably the most advanced architecture I've ever seen. It also definitely presents a significant performance level above both the K6 and P6 architectures, despite the claims of some skeptical high profile microprocessor reviewers.
Throughout I will be comparing the K7 to the 21264, and the P6 cores. The following are reference diagrams for each of the architectures found in documentation supplied by the vendors. The mark ups contain what I consider to be the most important considerations from a programming point of view, which are explained in greater detail below. Red markings indicate a slow or previous generation feature. Green markings indicate a fast or "state of the art feature".
The K7
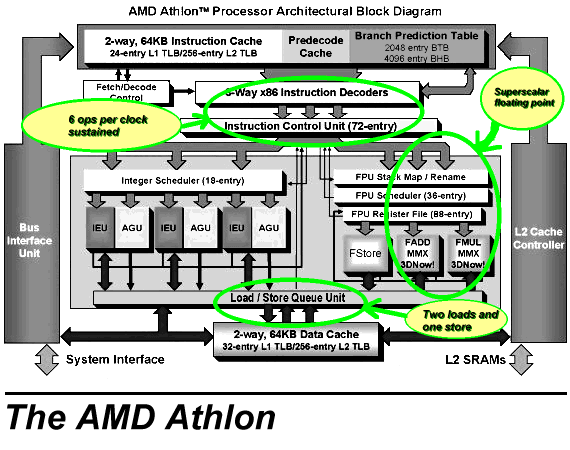
This is the latest x86 compatible architecture from AMD. It is instruction set compatible with Intel's Pentium II CPUs. It uses instruction translation to convert the cumbersome x86 instruction set to high performance RISC-like instructions, and drives those RISC instructions with a state of the art microarchitecture.
Update: This is not meant to contradict Dirk Meyer who claimed that "With the K7, the central quantum of information that floats around the machine is not decomposed RISC operations, it is a macro operation." Its really just a matter of perspective. The ALUs in the K7 don't understand "macro operations", they understand individual operations akin to the RISC86 ops in the K6. The macro operation bundles that are decoded are just a convenient structure inside of the K7 which gives much more complete coverage of the x86 instruction set (which have the net effect of delivering more operations to the function units per clock.) Each bundle is itself dispatched as separate operations to the ALUs as individual execution morsels (I'd still call this decomposition to risc ops myself.)
I'm sure the reason Dirk is saying that this is not just an x86 to RISC translation is because the internal mechanisms by which the K7 does its translation has no resemblance to the way either the K6 or P6 perform their translation. Thus for marketing reasons it is important for AMD to differentiate the way the K7 works from these previous generation chips. I'm just speculating on this last part of course -- for all I know "translation from x86 to RISC" may be a technical term with a hard and fast definition that puts me clearly in the wrong. :)
The 21264
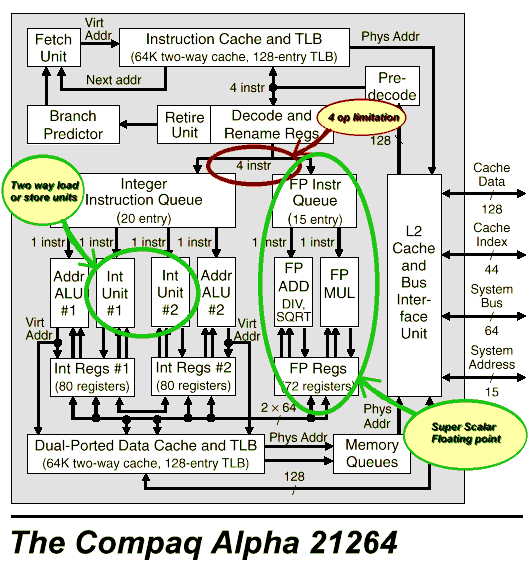
This is the latest incarnation of the DEC Alpha. Its a no holds barred advanced architecture, that is out-of-order and highly superscalar. It is fairly well recognized as the fastest microprocessor on earth by the industry standard SPEC benchmark.
The P6
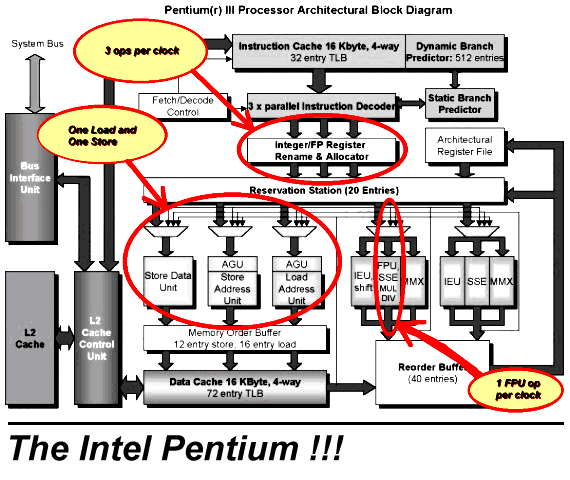
This is Intel's latest incarnation of their Pentium Pro architecture. It also translates x86 instructions into RISC-like instructions which are executed by an advanced out-of-order core.
General Architecture
The Athlon is a long pipelined architecture, and like the P6, does a lot of work to unravel some of the oddball conventions of the x86 instruction architecture in order to feed a powerful RISC-like engine.
The Athlon starts out with 3 beefy symmetrical direct path x86 decoders that are fed by highly pipelined instruction prefetch and align stages. The direct path decoders can take short x86 instructions as well as memory-register instructions. The instructions are translated to Macro-Ops which themselves contain two packaged ops (one being one of: load, load/store, store, and the other being an alu op.) Thus the front end of the K7 can realistically maintain up to 6 ops decoded per clock. (The decoders also can sustain up to one vector path decode per clock for the rarely used weird x86 instructions.)
The K7 has a 72 entry instruction control unit (so that's up to 144 ops, which is significantly more than the P6's 40 entry reorder buffer) in addition to an 18 entry integer reservation station as well as a 36 entry FPU reservation station. Holy cow. The K7 will do an awful lot of scheduling for you, that's for sure.
Now, the K7 has two load and one store ports into the D-cache (the P6 core can sustain a throughput of one load and/or store per clock.) However, algorithms are rarely store limited. Furthermore stores can be retired before they are totally completed. So I hesitate to stick with the 6 ops sustained rate. Instead its more realistic to consider it as 5 ops sustained with free stores. (Note that for comparison purposes, this is being very generous to the P6 core's estimated 3 ops per clock sustained rate of execution since it actually executes stores as two micro-ops. This would be equivalent to only two AMD RISC86 ops per clock throughput on code which is more store limited.)
After this point, the instructions are simply fed into fully pipelined instruction units (except, presumably, instructions that are microsequenced.) So indeed 5 ops is the K7's sustained instruction throughput. This is superior to the P6 architecture in that (1) it can supply an additional ALU op per clock (hence 50% more calculation bandwidth) (2) it can actually execute up to two additional ops per clock (that's 67% more total general execution bandwidth), and (3) it can service the ever important dual load case (this is twice the load bandwidth of the P6 architecture.) So like its predecessor the K6, the instruction decoders and back ends look fairly well balanced, except that with the K7 we have a significantly wider engine.
The 21264 is a 4-decode machine with separate load and alu instructions. The 21264 pipeline is structured with a maximum of 2 memory, integer, or FP instructions, from which any combination of executing 4 can be sustained per clock. So while the K7 has a higher total ops issued per clock, the 21264 has the advantage in the one case of 2 integer and 2 floating point instructions sustained per clock configuration. In reality this would not come up very often, however, conversely neither would many of the memory operanded instruction combinations on the K7. The K7 has the advantage of being able to execute 3 integer or 3 floating point ops, but that is balanced by the fact that the K7 has fewer registers and in reality only 2 "real work" floating point ops can be executed.
It is a remarkably difficult call to decide between the 21264 and the K7 as to which has the higher expected execute bandwidth which in of itself is a very impressive level for the K7 to have attained.
Branch Prediction
For branch prediction AMD went with the GShare algorithm with a large number of entries -- 2048 entry branch target buffer in addition to a 4096 entry branch history buffer. This differs from the K6's sophisticated history per branch combined with recent branch history algorithm and a branch target cache. AMD's claims are that the K7's algorithm achieves 95% prediction accuracy (similar to the K6.) Given the long pipelined architecture of the K7, using a very accurate predictor seems more necessary than it was on the K6. Like the P6 core, the K7 also loses a decode clock on any taken branch (because it does not use a branch target cache like the K6 does.) However, the high decode bandwidth of the Athlon will typically make this a non issue.
Back of envelope calculation
Plugging into our equation once again we see:
(95% * 0) + (5% * 10) = 0.5 clocks per loop
Hey, that's not too bad! Remember that the K6 didn't really beat 0.5 clocks due to the relatively larger impact on instruction decode bandwidth of the branch instruction itself. So the K7 appears to have the same expected average branch penalty as the K6! That's quite good for a deeply pipelined architecture. Its better than the P6 which has a worse predictor (90% accuracy) and larger miss penalty (13+ clocks).
Floating Point
There has been a lot of talk about the K7's floating point capability. Especially given the poor reputation of Intel's x86 competitors on floating point. The interest in the K7's floating point probably overshadowed any other feature.
I think AMD knew they had to deliver on floating point or forever suffer the backlash of the raving lunatics that would be denied their Quake frame rate being pegged at the monitor's refresh rate. And there is no question that AMD has delivered. On top of being fully pipelined (the P6 is partially pipelined when performing multiplies) AMD had the gall to make a superpipelined FPU. I would have thought that this was impossible given the horribly constipated x87 instruction set, but I was shocked to find that its really possible to execute well above one floating point operations per clock (on things like multiply accumulates.)
The K7 architecture shows a three-way pipeline (FADD, FMUL, and FSTORE) for the FPU however, "FSTORE" does not appear to be all that important (its used for FST(P), FLD(CONST) and "miscellaneous" instructions.) So the only question you'd think remains is "how fast is FXCH"? However, upon reflection it seems to me that the use of FXCH is far less important with the K7.
Since the K7 can combine ALU and load instructions with high performance, pervasive use of memory operands in floating point instructions (which reduces the necessity of using FXCH) seems like a better idea than the Intel recommended strategies.
A floating point test I did that uses this strategy confirms that the K7 is indeed significantly faster than the P6's floating point performance. My test ran about 50% faster. I suspect that as I become more familiar with the Athlon FPU I will be able to widen that gap (i.e., no I can't show what I have done so far.)
Nevertheless the top two stages of the FPU pipeline are stack renaming then internal register renaming steps. The register renaming stage would be unnecessary if FXCH (which helps treat the stack more like a register file) did not execute with very high bandwidth so I can only assume that FXCH must be really fast. Update: The latest Athlon optimization guide says that FXCH generates a NOP instruction with no dependencies. Thus it has an effective latency of 0-cycles (though it apparently has an internal latency or 2 clocks -- I can't even think of a way to measure this.)
Holy cow. Nobody in the mainstream computer industry can complain about the K7's floating point performance.
The 21264 also has two main FP units (Mul and Add) on top of a direct register file. So while the 21264 will have better bandwidth than the K7 on typical code which has been optimized in the Intel manner (with wasteful FXCHs) on code fashioned as described above, I don't see that the Alpha has much of an advantage at all over the K7. Both have identical peak FP throughput of 2 ops per clock, that in theory should be able to be sustainable by either processor.
As far as SIMD FP goes, AMD is sticking to their guns with 3DNow! (Although they did add the integer MMX register based SSE instructions -- it appears as though this was just to ensure that the Pentium-!!! did not have any functional coverage over the Athlon.) They did add 5 "DSP functions" which are basically 3 complex number arithmetic acceleration instructions as well as two FP <-> 16 bit integer conversion instructions. The two way SIMD architecture seems to be a perfect fit for complex numbers.
Other than these new instructions, there does not seem to be any architectural advantage to the K7 implementation of 3DNow! over the K6's 3DNow! implementation. I don't think this should be taken as any kind of negative against AMD's K7 designers, however. 3DNow! is one of those architectures that appears to be naturally implemented in only one way: the fastest way. So its not surprising that the K6 is as fast as the K7 in SIMD FP right out of the chute. (In the real world the K7 should be faster on 3DNow! loops due to better execution of necessary integer overhead instructions.)
On the surface it appears as though the SIMD capabilities of the Pentium !!!'s full SSE implementation better alleviates register pressure over the K7. However the K7 has the opportunity to pull even with SSE in this area as well by virtue of its use, once again, of memory operands. (The theoretical peak result throughput of SSE and 3DNow! are identical -- each has slight advantages over the other which on balance are a wash.)
Comparatively speaking, the Alpha has only added special acceleration functions for video playback. I am not familiar with the Alpha's extensions however I am under the impression that they did not add a full SIMD FP or SIMD integer instruction set.
Cache
The K7's cache is now 128 KB (2-way, harvard architecture, just like the Alpha 21264.) Ok this is just ridiculous -- the K7 has 4 times the amount of L1 cache as Intel's current offerings. If somebody can give me a good explanation as to why Intel keeps letting itself be a victim to what appears to be a simple design choice for AMD, I'd like to hear it.
The load pipe has increased from 2 cycle latency on the K6 to 3 cycle latency on the K7. This matches up with the P6 which also has a 3 cycle access time to their L1 cache. (But recall that the K7 can perform two loads per clock which is up to twice as fast as the K6 or P6.)
The K7 has a 44 entry load/store queue. (Holy cow.) Well, that ought to support plenty of outstanding memory operations.
Although starting from a 512K on-PCB L2 cache, AMD claims the ability to move to caches as large as 8MB. It should be obvious that AMD intends to take the K7 head to head against Intel's Xeon line. Off the PCB card, the K7 bus (which was actually designed by the Compaq Alpha team for the 21264) can support 20 outstanding transactions.
This all looks like top notch memory bandwidth to me.
Other
The AMD Athlon optimization guide is an amazing piece of work. Besides including a good description of the micro architecture, it takes a very pragmatic approach to presenting optimization tips. Basically there are just a few pitfalls to avoid. These pitfalls are easily worth the trade off for the benefit of essentially not having to worry about decode bandwidth at all.
It comes with a brief description on optimizing 64 bit arithmetic (which is becoming an issue for C++ compilers which support the long long data type) as well as numerous examples of high and low level optimizations. The recommendations are insightful. Not only will reading it will convince you of the awesome power of the Athlon processor, but it just might give you some good general programming optimization ideas.
I would recommend this guide to anyone interested in optimizing for the next generation of processors.
The AMD Athlon optimization guide
Brass Tacks
Holy cow! Did I mention that this thing was released at 650Mhz! That's a clear, uncontested 50Mhz lead over Intel. Although it has been suggested that this was simply a premature announcement meant to steal the limelight away from Intel (which has only recently started shipping the Pentium !!! at 600Mhz) they also said that 700Mhz was on its way (Q4 '99). I find it easier to believe that they are telling the truth (something some stockholder lawsuits should be motivating from them) than lying to this extent.
AMD has previously announced its intention to fabricate the K7 in a copper based process (which they gained from their strategic alliance with Motorola) in combination with a 0.18 micron technology. I'm not a hardware guy, so I don't really know what all this means, however, I have assurances (I read it in MicroDesign Resources) that it is leading edge process technology which will one way or another translate to higher frequencies. (Surprisingly, Intel will not switch over to copper in their initial 0.18 process.)
I think AMD's challenge from here is to try and figure out exactly what markets it can grow the Athlon into. Its too expensive for sub-$1K PCs and its not quite ready for SMP. Its also currently only available in 512K L2 cache configurations, so they can't go right after the Xeon market space just yet. While the Athlon is a great processor, its clear that AMD needs to complete the picture with their intended derivatives (the Athlon Select for the low end, the Athlon Ultra for servers, and the Athlon Professional for everyone else, as AMD have themselves disclosed) to take the fight to Intel in every segment.
Taken in total, the number of improved features of the K7 over previous generation processors leaves little doubt that in fact the K7 is truly a 7th generation processor. You don't have to take my word for it though. There are plenty of reviews that show benchmark after benchmark with the K7 absolutely creaming the contemporary P6. So 7th generation it is.
Versus the P6
The K7 is larger faster and better in just about every way. The Athlon simply beats the P6, even on code tweaked to the hilt for the P6 architecture. From the architecture, the Athlon should be able to execute any combination of optimized x86 code at least as efficiently as the P6. Code optimized specifically for the K7 should increase the performance gap between these two processor substantially.
Versus the 21264
From a pure CPU technology point of view this one is too close to call. Both have extremely comparable features with slightly different tradeoffs that should not, by themselves tip the balance either way. However at the end of the day the 21264 cannot be denied the official crown. The Alpha processors have the advantage that Compaq has developed the compilers themselves and they are 64bit on the integer side. They also have a much cleaner floating point instruction set architecture and use a higher end, more expensive infrastructure. AMD is stuck with the 32 bit instruction set defined by Intel as well as the software which has followed the optimization rules dictated by Intel's chips.
The only counter-balance that the K7 has is the MMX and 3DNow! instruction sets (in addition to the new instructions that have been added) which give the K7 the advantage for multimedia.
Nevertheless its amazing how close the x86 compatible K7 comes. For a developer writing something from scratch going for 21264-like performance should be the goal to shoot for.
Update: In recent months both Intel and AMD have overtaken the Alpha in clock speed by a substantial amount, and consequently in terms of real integer performance as well. While their roadmap still shows higher clocked versions of the 21264 in the future, it looks like Compaq is concentrating their efforts on symmetric multithreading (something they presented at MicroProcessor Forum in 1999.)
| The Willamette |
On 02/15/00, at the Intel Developer Forum a very brief preview of the Willamette architecture was given. Since that time other details have surfaced, and more analysis has been done. However Intel has not yet fully unveiled all the details of the architecture. As such, the analysis below is preliminary.
The architecture is a 20-stage deep pipeline, with the claimed purpose being for clock rate scaling reasons. However this pipeline is very different from x86 processors designed up until this point. The top few stages feed from the on-chip L2 cache straight into a one-way x86 decoder which feeds EIP and micro-ops into something called a trace cache. This trace cache replaces the processor's L1 I-cache. The trace cache then feeds micro-ops at a maximum rate of 3 per clock (actually 6 micro-ops every other clock) in instruction order (driven by a trace-cache-local branch predictor as necessary) into separate integer and FP/multimedia schedulers (much like the Athlon, except that the rate is higher for the Athlon.) This mechanism effectively serves the same purpose of the combination the Athlon's Instruction Control scheduler and I-cache (including predecode bits.) Because the x86 decoder is applied only upon entry into the trace cache, its performance impact is analogous to an increase in I-cache line fill latency of other architectures. From an implementation point of view, Intel saves themselves from the need to making a superscalar decoder (something they have implemented in a clumsy way in the P6 and P5 architectures.)
Update: Just to make it clear -- one other thing this buys them is that the trace cache eliminates direct jumps, call and returns from the instruction stream. On the other hand, such instructions should not exist as bottlenecks in any reasonably designed performance software. These instructions are necessarily parallizable with other code.
The integer side is a two way integer ALU plus 1 load and 1 store units. But an important twist is that these computation stages are clocked at double the clock rate of the base clock for the CPU. That is to say, the ALUs complete their computation stages at 0.5 clock granularities (with 0.5 latencies in the examples discussed). Results that complete in the earlier half of the clock can (in at least the described cases) be forwarded directly to a computation issued into the second half of the clock. (Intel calls this double pumping.) From this point of view alone, the architecture has the potential to perform double the integer computational work as the P6 architecture. However, since the trace cache can sustain a maximum of 3 micro-ops delivered per clock (which is the same as the maximum issue rate of the P6 architecture), there is no way for the integer units to sustain 4-micro-ops of computation per clock. Nevertheless, this is a shockingly innovative idea that does not exist in any other processor architecture that I have ever heard of.
I previously thought that the 0.5 clock granularities applied to loads (thus allowing two loads per clock). However, it has been clarified that in fact the load unit can accept only one new load per clock. This is consistent with other people's theories that the ALU clock doubling is synthesized at two fused adders which are not applicable to the load unit.
The L1 D-cache latency is a surprisingly low 2 clocks! This is very suggestive of simplifications in their L1-D cache design, or the load/store pipes. The Willamette software developer's guide says that 3-operanded, or scaled addressing should be avoided, which is in line with this theory.
Update: Leaked benchmarks indicate that there is some funny business going on in their L1 cache. While they claimed an L1 latency of 2 clocks, measurements indicate that it starts at 3 clocks (its possible they were ignoring the address calculations which in some cases can be computed in parallel with data access -- however, the Athlon architecture has the same feature.) The latency benchmark scores that were leaked indicate that as data size increase to 4K and beyond, the latency gradually increases rather than falling off in cliffs (as the data foot print size exceeds the size of one level of cache) like most other CPUs.
Update: Bizarrely, the Willamette has only 8K of L1 D-cache. This is a throwback to the 486 days. Paul DeMone offers as an explanation that the latency to the L1 D-cache really is 2-cycles and that when the total cache architecture is taken into account (the Willamette includes 256K of 7-cycle latency on chip L2 cache) the cache access rate is nearly identical to the projected performance for an Athlon Mustang which in turn has a superior cache access rate over the Athlon Thunderbird.
I don't completely buy this. One of the statement's Paul makes is: "However, given the fact that modern x86 processors can execute up to three instructions per cycle, the odds of finding up to 6 independent instructions to hide (or cover) the load-use latency is rather small." This is not exactly the right way to view the relationship between loads and computation ALU instructions. In modern x86's the decoder's rate of bytes => scheduled riscops exceeds the rate of ALU execution => retirement. The reason for this is that the amount of inherent parallelism in typical programs is less that what these CPUs are capable of doing. But, memory loads are different. Memory loads are dependent only address computation which usually is not dependent on the critical path of calculations in a typical algorithm (except when using slow data structures like linked lists.) So once a memory instruction is decoded and scheduled, it can almost always proceed immediately -- essentially always starting at the earliest possible moment. As long as the data can be returned before the scheduler runs out of other older work to do (which I claim it will have a lot of) then this latency will not be noticed. Said in another way, a deep scheduler can cover for load latency.
What does this mean? Well, I believe it means that shortening up the L1 D-cache latency while sacrificing the size so dramatically in of itself cannot possibly be worth it. I am more inclined to believe that the latency to the L2 cache (which may be strictly a D-cache) itself has shown itself to be short enough to benefit from the effect I referred to above. If the *L2* latency can be totally hidden as well, then the real size concern is not with the L1 D-cache but rather the L2 cache.
Update: Also presented was the fact that the CPU uses a 4x100 Mhz Rambus memory interface. While I ordinarily would ignore such bandwidth claims (for memory latency is usually more important, and when you need bandwidth you can use "prefetch" to hide the memory hits) leaks from some Intel insider on USENET suggest that Willamette will use some sort of linear address pattern matching prefetch mechanism. This is technique has apparently been used by other RISC vendors, however with mixed results. Benchmark leaks seem to confirm that Willamette will have bandwidth that is about double that of current SDRAM based Athlons (which is the current x86 leader on the Stream benchmark.)
The floating point is somewhat degraded in some features and somewhat improved in others relative to the P6 architecture. First off, the FPU is not double pumped like the integer unit. (So its reasonable to assume that double clocked circuit techniques have complexity constraints that prevent implementation in just any pipeline stage.) There are two FP issue ports; the first which does the real work (FADD, FMUL, etc) and the second which performs miscellaneous (FMOVE and FSTORE) operations. The FXCH instruction is no longer free -- it has real latency (I don't know the exact latency, but anything above an effective 0 clocks is bad), thus Intel will rely on Athlon-like FP scheduling strategies. However prevalent miscellaneous instructions like FLD and FST(P) are handled by in parallel to FADD/FMUL's which is an advantage over the way this was done on the P6 code. But as far as the real serious operations are concerned (FADD, FMUL) they have remained with a single pipelined FPU design. Apparently they have fully pipelined the FMUL though which is an improvement versus the P6 core (and it has the same 5 clock latency).
Update: Leaked benchmark score indicate that Willamette FPU appears to be a very weak performer (closer to a K6 than even a P6.) While it is possible that Intel has majorly screwed up their FPU design, this data point ties more closely with the fact that they claim to have booted Windows within weeks of receiving first silicon. As is well known, Intel employs a microcode update feature which allows them to change the implementation of some instructions. While this feature is not ordinarily used for the most common and high speed instructions, it seems likely to me, given the complexity of the design, that Intel would enable the potential use of this feature on *all* its instructions for first silicon. The nature of the trace cache also suggests that this might be done more easily on the Willamette than their previous generation architectures. So, my suspicion is that Intel screwed up one or more of its FPU instructions (maybe it just doesn't throw exceptions properly) and has had to replace it with a microcode substitute. This is *all* just speculation on my part. It will remain to be seen what the real FP performance of Willamette is when it ships.
Update: Intel has been heavily hyping the new SIMD instructions added to the Willamette (SSE-2). They have added a 2x64 packed floating point instruction set as well as 128 bit integer MMX instructions. However, if their multimedia computation can only be performed from one issue port (assuming that the FMOVE and FSTORE pipe is not capable of any calculations) then they have compromised their older 64 bit MMX performance (the P6 has dual MMX units) and will only maintain parity with their older SSE unit if they've reduced the number of micro-ops per instruction (which would necessitate a fully 128 bit wide ALU, instead of the two parallel 64 bit units in the Pentium-!!!.) The new 2x64 FP theoretically brings their "double FP" performance to parity with the Athlon's x87 FPU (again, this is contingent on single micro-ops per packed SSE-2 instruction). I say theoretically, because the algorithm needs to be fully vectorized into SIMD code just to keep up with what the Athlon can do in straight unvectorized (but reasonably scheduled) code. The 128 bit MMX, can at best match the performance of dual 64 bit MMX units which are present in the Athlon, K6, P55c and P-!!! CPUs. One thing they have added which is nice is a SIMD 32-bit multiplier to the integer side.
From an instruction point of view, Intel appears to be declaring victory (there are now more instructions as well as more coverage than even the AltiVec instruction set; with the exception of multiply accumulate, and lg/exp approximations), but I don't see the performance benefit of SSE-2. In fact I think there is a real possibility of a slight performance degradation here.
Although Intel correctly points out that x86 to micro-op decode penalties no longer affect branch mispredicts, the bulk of the pipeline stages in the architecture appear between the trace cache output and execution stages. Thus, the latency of a branch mispredict (which basically needs to abort results from trace cache output to execution) has worsened and in fact is worse than any other architecture I have ever heard of. As a counter to this, Intel has increased their branch target buffer to 4096 entries and is reportedly using an improved prediction algorithm ("...[the] Willamette processor microarchitecture significantly enhances the branch prediction algorithms originally implemented in the P6 family microarchitecture by effectively combining all currently available prediction schemes"). Intel has not commented on the prediction probabilities of the Willamette architecture. Intel has also added branch hint instructions.
Finally they claim to have a significantly larger scheduler (more than 100 instructions can be in-flight at once.)
On the surface it appears as though the Willamette processor will do very well on integer code with lots of dependencies, however, will not fair as well as the Athlon on floating point. Other factors such as trace cache and L1 D-cache size and the quality of the branch predictor remain unknown.
Update: Norbert Juffa has written to me
indicating that the P4 has other odd problems:
I.e. pretty much all the instructions useful for branch conversion are slow. So one
has the choice between "slow" and "utterly slow" when dealing with hard to predict
branches. It seems that all operations that consume flags are slow on P4. At minimum
that's true for operations consuming the carry flag, but for CMOV I also tried the ZF
with identical results so I think it's flag-consuming instructions in general that are being
penalized.
So a somewhat clearer picture of the P4 is starting to form. While in the
most optimistic situations (just direct adds, or logical instructions) the P4
probably motors quite tremendously, just about every slight offshoot
instruction (shifts, rotates, flag consuming instructions, etc) seem to take
a severe penalty. Some people have written that future compiler work
(specifically Intel's compiler effort, presumably) will remove the negative
effects of these slower instructions (presumably by not using them) but that
will prove to be rather difficult in many situations.
As Norbert points out above, unpredictable branches are a serious problem in
modern CPU cores. If the branch is unpredictable, it behooves the programmer
to find a way out -- typically by two sided computation then a mix in with one
of the above instructions. In the P4's case, one can be forced to choose
between the above instructions or a 19 clock prediction penalty (assuming
the branch is still luckily predicted about 50% of the time, that's an
average of 9.5 clocks for the unpredictable branch) and one of the above
instructions. Compare this to the Athlon which can run these instructions at
a rate of 3 per clock (though with only one EFLAGs register its unlikely that
more than one would ever be used or needed)!
Shifts and rotates (which apparently have the same problem), while being
somewhat uncommon instructions, do show up in certain key applications
(symmetric crypto, hashing, CRCs, random number generators and various other
kernels) and are not really substitutable except in the most trivial cases.
One can see this in the various benchmarks results when pitting the P4 against
the Athlon. The Athlon, though severely outgunned in raw clock rate, has no
trouble trouncing the P4 in some applications, while in other applications the
P4 relies almost totally on its clock rate advantage to win. I have yet to
see a benchmark showing Intel's "NetBurst" architecture (the double pumped
integer ALUs I mean) show up to real take the lead. Given its current clock
rate advantange, the upgrades in Intel's compilers, and the years its had now
to find the right applications, I would have fully expected that Intel would
have several show case applications that demonstrated the latest P4 with
roughly 3 times the performance of the latest Athlon.
But it hasn't happened. Since I don't have a P4 to analyze this deeply
myself, I cannot look into the details myself. And by this time, it looks
like the next avenue to be looking at will be 64 bit CPUs.
On 01/19/00, the Transmeta processor
architecture "Crusoe" was at least partially unveiled. Because of the relative
dearth of information on it, I will just roughly describe it with only
a few comments.
The Crusoe is the ultimate in x86 "emulation".
The core chip is not an x86 compatible CPU at all, but rather a VLIW engine.
The engine runs an emulation program (the Code Morpher) which reads
x86 instructions and compiles them to VLIW code snippets, then executes
the compiled snippets. The compiler uses continuous on the fly profiling
feedback to decide which code snippets need to be analyzed the most. This
design probably gets the most bang for the buck in terms of performance
per clock invested in the translation problem. Unlike other technologies
like FX!32 or Bochs, Crusoe has been clearly designed for 100% x86 compatibility
from boot to shutdown (hence esoteric protected mode instructions are emulated
in a compatible way -- device drivers will be written in x86 binaries,
not native Crusoe binary).
This contorted way of executing x86 buys
them a number of things. (1) They have complete freedom in how the VLIW
core is designed. For example, it does not even have to have robust register
access -- if it takes two clocks for an operation to finish, then rather
than stalling subsequent accesses to the output register, perhaps the value
is old or undefined for the immediately subsequent clock and updated on
the second clock. But more importantly, as they target better and better
process technologies, they can change most aspects of their design without
compromising x86 compatibility. (2) It is possible to find optimizations
that the original software authors, or their compilers did not find in
their binary code. You can imagine that at least some x86 code might
end up substantially faster on the Crusoe. (3) The VLIW engine is very
small and very simple -- thus it is easier to analyze from a performance
point of view, and consequently should be easier to design for higher frequencies
of operation. (4) It is not necessary to design an out-of-order execution
core; the translation software will take care of re-ordering instructions.
This is not 100% ideal since it is unlikely to be able to detect fine grain
dynamic behaviors (for example, one could arrive at a branch target in
a number of ways, and thus the machine might be in a variety of different
states that are not all best served with a single subsequent instruction
ordering.) (5) Bugs in "Crusoe" (either hardware or software) can be worked
around even on *already deployed* systems. In the words of one TransMeta
employee: "Actually, we can [work around hardware and software bugs].
Obviously not for *ALL* kinds of bugs (if the chip can't add, it's pretty
useless), but in fact the software layer not only can, but *DOES* work
around several errata in the pre-production TM5400 samples that would have
been fatal without the abstraction layer. The performance impact, incidentally,
is negligible -- too small to be measured." This will give them
more options for ensuring the correctness of their solution that can potentially
shorten their design turn around time.
The bad news is that their initial clock
rates of 300-400Mhz are not very compelling, and the promise of 500-700Mhz
in 6 months is kind of so-so, given that the desktop competition is now
at 800Mhz. There were no pure performance benchmarks shown which is indicative
that they probably are not achieving performance per cycle parity with
Intel or AMD. The good news is that this part is being positioned in the
mobile space. The (apparent) maximum power draw is an amazing 2W, which
will make for very battery friendly notebooks. They also seem to be targeting
the "internet appliance market" but I don't take that too seriously (the
"internet appliance market" that is.)
The white papers suggest that the VLIW engine
drives 4 instructions in parallel in a strict [ALU, ALU, MEM, BRANCH]
format. Hmmm ... this looks roughly comparable to a K6 to me (a little
better with branches, a little worse with memory.)
One thing they definitely have introduced
which is interesting is the idea of a speculative non-aliased memory window
mechanism. What happens is that the morpher can rearrange loads and stores
in more optimal orders, and the legality of this is checked with a special
speculation checkpoint instruction. So like branch prediction, if a late
determination is made that the memory reordering was wrong, then an interrupt
is thrown and the "wrongly executed" block of instructions can be undone.
Of course, the goal is not to take advantage of this speculative undoing
(back to the checkpoint instruction), but rather just to use it as a parachute
to ensure robustness, in the hopes that in most cases for a given fragment
of code, memory reordering is a valid thing to do. This is a big deal.
This problem has plagued CPU designers and compiler writers for decades.
The fact that these guys have implemented a solution for this, is indicative
that they are very serious designers with some good ideas. The idea fits
very well with their code morpher because for degenerate cases where load/store
reordering never works, the morpher can detect this and throw the whole
idea out for that fragment of code.
Its not entirely clear how much of a long
term advantage this is, though. Apparently there is at least one other
CPU architecture (HP's PA-RISC 8500) that has implemented Load/Store
speculative ordering. So there's no telling how long Transmeta might be able
to hold onto this advantage until the same technology makes it into
conventional x86 architectures.
I really don't think these guys are at all
going to seriously contend with the Athlon in any kind of head to head,
so I will avoid making any kind of direct comparison. Given the translation
architecture, I don't think that further discussion of processor features
(like branch prediction, cache or floating point) will make too much sense.
We're going to have to wait until we can play with it before we can get
a real idea of what it can do.
Before I leave this, there is the thought
that somehow the Transmeta chip would be able to execute other instruction
sets in a different configuration or perhaps more interestingly simultaneously
with an x86. The presentation seemed to steer towards the direction of
"we are only emulating x86's". However, public statements made by Transmeta
employees lead to a different possibility: "There was a TM3120 running
Doom on Linux. Doom was compiled mostly to x86, except for the inner loop,
which was compiled to picoJava using Steve Chamberlain's picoJava back-end.
The whole program was linked together using a magic linker. When the program
had to enter the inner loop, it executed a reserved x86 opcode which jumped
to picoJava mode. The inner loop then executed picoJava bytecode until
it was done, and re-entered x86 mode."
This is very suggestive, at least to me,
that they will support Java (or perhaps just picoJava) on their CPUs that
would likely be substantially faster than the current crop of x86 based
Java virtual machines.
[Major aside:] Here's my guess as to its
implementation: (1) The picoJava VM relies entirely on a host x86 program
to manage memory for it. (2) The picoJava VM would be able to read and
write x86 state through special APIs, however, in ordinary operation be
otherwise totally isolated from the x86 state and vice versa. (3) The only
entry method for the x86 into picoJava mode is a reserved opcode. (4) All
interrupts need to be able to know which execution state the code morphing
environment is in, to be able to swap between the virtual x86 state and
the virtual picoJava state. (Essentially multitask between the two code
morphing tasks.)
Actually this sounds like it would be
quite cool -- the x86 based JVM wrapper code would have an inner loop that
looked like:
For their technology demo, I wouldn't
be surprised if they didn't simply allocate some fixed physical memory,
and disallowed interrupts for the duration of the picoJava code.
Willamette
Processor Software Developer's Guide
The 6th generation
of CPUs
Anyhow, I was exploring execution speeds and specifically how to avoid the high
branch mispredict penalty for poorly predicted branches (19 cycles). To my utter
frustration, I discovered that
SBB has latency of 6 cycles
CMOVcc has latency of 5 cycles
SETcc has latency of 5 cycles
The
Transmeta Media Processor
;// Set up memory space for picoJava as well as
;// the entry point in one of the x86 registers.
jmp L2
L1:
cmp eax,[eax] ;// Force OS to load page.
L2:
TM_OPCODE(picoJava)
jnc L1
;// Do some kind of Meta functions like "exit"
;// switch( eax ) { ... } jmp L2
So that when the picoJava machine wanted
to read a memory page it would simply switch back to x86 mode clearing
the carry flag and loading the address into the eax register. When the
picoJava code snippet was done it could switch to x86 mode, setting the
carry flag and an "exit command" into one of the x86 registers. When the
picoJava environment wanted more memory, or to free memory it would set
the carry flag and an "allocate memory" command.
Glossary
of terms
Links
Tom's
hardware guide review of the Athlon
Inside
The KLAT2 Supercomputer: The Flat Neighborhood Network & 3DNow!
ZDTV's
"Transmeta mystery revealed"
EETimes
analysis of Willamette
US6018786:
Trace based instruction caching
US6014742:
Trace branch prediction unit
Chip-Architect:
Comparison of Mustang and Willamette
Alpha Symmetric
Multithreading
How Stuff Works -- How Microprocessors Work


