
| 6th Generation CPU Comparisons. |
|
|
|
| AMD K6 | Intel Pentium II | Cyrix 6x86MX | Common features | Closing words | Glossary |
The following is a comparative text meant to give people a feel for the differences in the various 6th generation x86 CPUs. For this little ditty, I've chosen the Intel P-II (aka Klamath, P6), the AMD K6 (aka NX686), and the Cyrix 6x86MX (aka M2). These are all MMX capable 6th generation x86 compatible CPUs, however I am not going to discuss the MMX capabilities at all beyond saying that they all appear to have similar functionality. (MMX never really took off as the software enabling technology Intel claimed it to be, so its not worth going into any depth on it.)
In what follows, I am assuming a high level of competence and knowledge on the part of the reader (basic 32 bit x86 assembly at least). For many of you, the discussion will be just slightly over your head. For those, I would recommend sitting through the 1 hour online lecture on the Post-RISC architecture by Charles Severence to get some more background on the state of modern processor technology. It is really an excellent lecture, that is well worth the time:
| The AMD K6 |

This seems remarkably simple considering the features that are claimed for the K6. The secret, is that most of these stages do very complicated things. The light blue stages execute in an out of order fashion (and were colored by me, not AMD.)
The fetch stage, is much like a typical Pentium instruction fetcher, and is able to present 16 cache aligned bytes of data per clock. Of course this means that some instructions that straddle 16 byte boundaries will suffer an extra clock penalty before reaching the decode stage, much like they do on a Pentium. (The K6 is a little clever in that if there are partial opcodes from which the predecoder can determine the instruction length, then the prefetching mechanism will fetch the new 16 byte buffer just in time to feed the remaining bytes to the issue stage.)
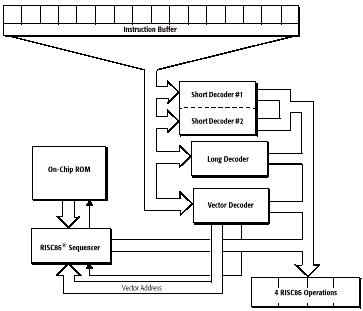
The decode stage attempts to simultaneously decode 2 simple, 1 long, and fetch from 1 ROM x86 instruction(s). If both of the first two fail (usually only on rare instructions), the decoder is stalled for a second clock which is required to completely decode the instruction from the ROM. If the first fails but the second does not (the usual case when involving memory, or an override), then a single instruction or override is decoded. If the first succeeds (the usual case when not involving memory or overrides) then two simple instructions are decoded. The decoded "OpQuad" is then entered into the scheduler.
Thus the K6's execution rate is limited to a maximum of two x86 instructions per clock. This decode stage decomposes the x86 instructions into RISC86 ops.
This last statement has been generally misunderstood in its importance (even by me!) Given that the P-II architecture can decode 3 instructions at once, it is tempting to conclude that the P-II can execute typically up to 50% faster than a K6. According to "Bob Instigator" (a technical marketroid from AMD) and "The Anatomy of a High-Performance Microprocessor A Systems Perspective" this just isn't so. Besides the back-end limitations and scheduler problems that clog up the P-II, real world software traces analyzed at Advanced Micro Devices indicated that a 3-way decoder would have added almost no benefit while severely limiting the clock rate ramp of the K6 given its back end architecture.
That said, in real life decode bandwidth limitation crops up every now and then as a limiting factor, but is rarely egregiously in comparison to ordinary execution limitations.
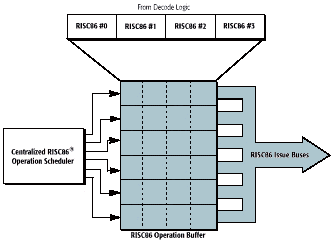
The issue stage accepts up to 4 RISC86 instructions from the scheduler. The scheduler is basically an OpQuad buffer that can hold up to 6 clocks of instructions (which is up to 12 dual issued x86 instructions.) The K6 issues instructions subject only to execution unit availability using an oldest unissued first algorithm at a maximum rate of 4 RISC86 instructions per clock (the X and Y ALU pipelines, the load unit, and the store unit.) The instructions are marked as issued, but not removed until retirement.
The operand fetch stage reads the issued instruction operands without any restriction other than register availability. This is in contrast with the P-II which can only read up to two retired register operands per clock (but is unrestricted in forwarding (unretired) register accesses.) The K6 uses some kind of internal "register MUX" which allows arbitrary accesses of internal and commited register space. If this stage "fails" because of a long data dependency, then according to expected availability of the operands the instruction is either held in this stage for an additional clock or unissued back into the scheduler, essentially moving the instruction backwards through the pipeline!
This is an ingenious design that allows the K6 to perform "late" data dependency determinations without over-complicating the scheduler's issue logic. This clever idea gives a very close approximation of a reservation station architecture's "greedy algorithm scheduling".
The execution stages perform in one or two pipelined stages (with the exception of the floating point unit which is not pipelined, or complex instructions which stall those units during execution.) In theory, all units can be executing at once.
Retirement happens as completed instructions are pushed out of the scheduler (exactly 6 clocks after they are entered.) If for some reason, the oldest OpQuad in the scheduler is not finished, scheduler advancement (which pushes out the oldest OpQuad and makes space for a newly decoded OpQuad) is halted until the OpQuad can be retired.
What we see here is the front end starting fairly tight (two instruction) and the back end ending somewhat wider (two integer execution units, one load, one store, and one FPU.) The reason for this seeming mismatch in execution bandwidth (as opposed to the Pentium, for example which remains two-wide from top to bottom) is that it will be able to sustain varying execution loads as the dependency states change from clock to clock. This at the very heart of what an out of order architecture is trying to accomplish, being wider at the back-end is a natrual consequence of this kind design.
Additional stalls are avoided by using a 16 entry times 16 byte branch target cache which allows first instruction decode to occur simultaneously with instruction address computation, rather than requiring (E)IP to be known and used to direct the next fetch (as is the case with the P-II.) This removes an (E)IP calculation dependency and instruction fetch bubble. (This is a huge advantage in certain algorithms such as computing a GCD; see my examples for the code) The K6 allows up to 7 outstanding unresolved branches (which seems like more than enough since the scheduler only allows up to 6 issued clocks of pending instructions in the first place.)
The K6 benefits additionally from the fact that it is only a 6 stage pipeline (as opposed to a 12 stage pipeline like the P-II) so even if a branch is incorrectly predicted it is only a 4 clock penalty as opposed to the P-II's 11-15 clock penalty.
One disadvantage pointed out to me by Andreas Kaiser is that misaligned branch targets still suffer an extra clock penalty and that attempts to align branch targets can lead to branch target cache tag bit aliasing. This is a good point, however it seems to me that you can help this along by hand aligning only your most inner loop branches.
Another (also pointed out to me by Andreas Kaiser) is that such a prediction mechanism does not work for indirect jump predictions (because the verification tables only compare a binary jump decision value, not a whole address.) This is a bit of a bummer for virtual C++ functions.
This all means that the average loop penalty is:
(95% * 0) + (5% * 4) = 0.2 clocks per loop
But because of the K6's limited decode bandwidth, branch instructions take up precious instruction decode bandwidth. There are no branch execution clocks in most situations, however, branching instructions end up taking a slot where there is essentially no calculations. In that sense K6 branches have a typical penalty of about 0.5 clocks. To combat this, the K6 executes the LOOP instruction in a single clock, however this instruction performs so badly on Intel CPUs, that no compiler generates it.
More complex instructions such as FDIV, FSQRT and so on will stall more of the units on the P-II than on the K6. However since the P-II's scheduler is larger it will be able to execute more instructions in parallel with the stalled FPU instruction (21 in all, however the port 0 integer unit is unavailable for the duration of the stalled FPU instruction) while the K6 can execute up to 11 other x86 instructions a full speed before needing to wait for the stalled FPU instruction to complete.
In a test I wrote (admittedly rigged to favor Intel FPUs) the K6 measured to only perform at about 55% of the P-II's performance. (Update: using the K6-2's new SIMD floating point features, the roles have reversed -- the P-II can only execute at about 70% of a K6-2's speed.)
An interesting note is that FPU instructions on the K6 will retire before they completely execute. This is possible because it is only required that they work out whether or not they will generate an exception, and the execution state is reset on a task switch, by the OS's built-in FPU state saving mechanism.
The state of floating point has changed so drastically recently, that its hard to make a definitive comment on this without a plethora of caveats. Facts: (1) the pure x87 floating point unit in the K6 does not compare favorably with that of the P-II, (2) this does not tend to always reflect in real life software which can be made from bad compilers, (3) the future of floating point clearly lies with SIMD, where AMD has clearly established a leadership role. (4) Intel's advantage was primarily in software that was hand optimized by assembly coders -- but that has clearly reversed roles since the introduction of the K6-2.
Like the P-II, the K6's cache is divided into two fixed caches for separate code and data. I am not as big a fan of split architectures (commonly referred to as the Harvard Architecture) because they set an artificial lower limit on your working sets. As pointed out to me by the AMD folk, this keeps them from having to worry about data accesses kicking out their instruction cache lines. But I would expect this to be dealt with by associativity and don't believe that it is worth the trade off of lower working set sizes.
Among the design benefits they do derive from a split architecture is that they can add pre-decode bits to just the instruction cache. On the K6, the predecode bits are used for determining instruction length boundaries. Their address tags (which appears to work out to 9 bits) point to a sector which contains two 32 byte long cache lines, which (I assume) are selected by standard associativity rules. Each cache line has a standard set of dirty bits to indicate accessibility state (obsolete, busy, loaded, etc).
Although the K6's cache is non-blocking, (allowing accesses to other lines even if a cache line miss is being processed) the K6's load/store unit architecture only allows in-order data access. So this feature cannot be taken advantage of in the K6. (Thanks to Andreas Kaiser for pointing this out to me.)
In addition, like the 6x86MX, the store unit of the K6 actually is buffered by a store Queue. A neat feature of the store unit architecture is that it has two operand fetch stages -- the first for the address, and the second for the data which happens one clock later. This allows stores of data that are being computed in the same clock as the store to occurr without any apparent stall. That is so darn cool!
But perhaps more fundamentally, as AMD have said themselves, bigger is better, and at twice the P-II's size, I'll have to give the nod to AMD (though a bigger nod to the 6x86MX; see below.)
The K6 takes two (fully pipelined) clocks to fetch from its L1 cache from within its load execution unit. Like the original P55C, the 6x86MX spends extra load clocks (i.e., address generation) during earlier stages of their pipeline. On the other hand this compares favorably with the P-II which takes three (fully pipelined) clocks to fetch from the L1 cache. What this means is that when walking a (cached) linked list (a typical data structure manipulation), the 6x86MX is the fastest, followed by the K6, followed by the P-II.
Update: AMD has released the K6-3 which, like the Celeron adds a large on die L2 cache. The K6-3's L2 cache is 256K which is larger than the Celeron's at 128K. Unlike Intel, however, AMD has recommended that motherboard continue to include on board L2 caches creating what AMD calls a "TriLevel cache" architecture (I recall that an earler Alpha based system did exactly this same thing.) Benchmarks indicate that the K6-3 has increased in performance between 10% and 15% over similarly clocked K6-2's! (Wow! I think I might have to get one of these.)
Anyhow, this design is very much in line with AMD's recommendation of using complicated load and execute instructions which tend to be longer and would favor the K6 over the P-II. In fact, the AMD just seems better suited overall for the CISCy nature of the x86 ISA. For example, the K6 can issue 2 push reg instructions per clock, versus the P-II's 1 push reg per clock.
According to AMD, the typical 32 bit decode bandwidth is about the same for both the K6 and the P-II, but 16 bit decode is about 20% faster for the K6. Unfortunately for AMD, if software developers and compiler writers heed the P-II optimization rules with the same vigor that they did with the Pentium, the typical decode bandwidth will change over time to favor the P-II.
6x86MX seems to just let their pipelines accumulate with work moving only in a forward direction which makes them more susceptible to being backed up, but they do allow their X and Y pipes to swap contents at one stage.
Update: AMD's new "CXT Core" has enabled write combining.
As I have been contemplating the K6 design, it has really grown on me. Fundamentally, the big problem with x86 processors versus RISC chips is that they have too few registers and are inherently limited in instruction decode bandwidth due to natural instruction complexity. The K6 addresses both of these by maximizing performance of memory based in-cache data accesses to make up for the lack of registers, and by streamlining CISC instruction issue to be optimally broken down into RISC like sub-instructions.
It is unfortunate, that compilers are favoring Intel style optimizations. Basically there are several instructions and instruction mixes that compilers avoid due to their poor performance on Intel CPUs, even though the K6 executes them just fine. As an x86 assembly nut, it is not hard to see why I favor the K6 design over the Intel design.
The reason I have come to this conclusion is that the architecture of the chip itself is much more straight forward than, say the P-II, and so there is less explanation necessary. So the volume of documentation is not the only determining factor to measuring its quality.
If companies were interested in writing a compiler that optimized for the K6 I'm sure they could do very well. In my own experiments, I've found that optimizing for the K6 is very easy.
Recommendations I know of: (1) Avoid vector decoded instructions including carry flag reading instructions and shld/shrd instructions, (2) Use the loop instruction, (3) Align branch targets and code in general as much as possible, (4) Pre-load memory into registers early in your loops to work around the load latency issue.
Their marketting strategy of selling at a low price while adding features (cheaper Super7 infrastructure, SIMD floating point, 256K on chip L2 cache combined with motherboard L2 cache) has paid off in an unheard of level brand name recognition outside of Intel. Indeed, 3DNow! is a great counter to Intel Inside. If nothing else they helped create a real sub-$1000 PC market, and have dictated the price for retail x86 CPUs (Intel has been forced to drop even their own prices to unheard of lows for them.)
AMD has struggled more to meet the demand of new speeds as they come online (they seem predictably optimistic) but overall have been able to sell a boat load of K6's without being stepped on by Intel.
Previously, in this section I maintained a small chronical of AMD's acheivements as the K6 architecture grew, however we've gotten far beyond the question of "will the K6 survive?" (A question only idiots like Ashok Kumar still ask.) From the consumer's point of view, up until now (Aug 99) AMD has done a wonderful job. Eventually, they will need to retire the K6 core -- it has done its tour of duty. However, as long as Intel keeps Celeron in the market, I'm sure AMD will keep the K6 in the market. AMD has a new core that they have just introduced into the market: the K7. This processor has many significant advantages over "6th generation architectures".
The real CPU WAR has only just begun ...
Update: The IEEE Computer Society has published a book called "The Anatomy of a High-Performance Microprocessor A Systems Perspective" based on the AMD K6-2 microprocessor. It gives inner details of the K6-2 that I have never seen in any other documentation on Microprocessors before. These details are a bit overwhelming for a mere software developer, however, for a hard core x86 hacker its a treasure trove of information.
| The Intel P-II |
Intel has enjoyed the status of "defacto standard" in the x86 world for some time. Their P6/P-II architecture, while not delivering the same performance boost of previous generational increments, solidifies their position. Its is the fastest, but it is also the most expensive of the lot.
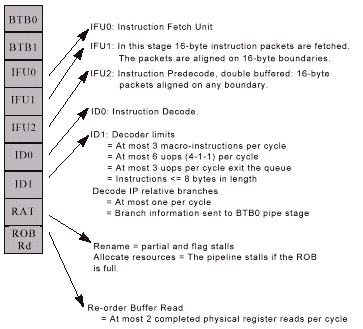
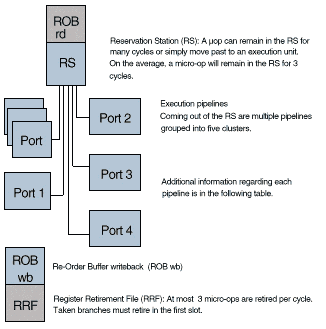
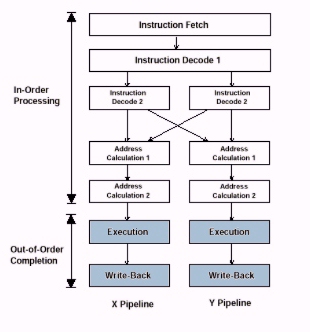
The P-II is a highly pipelined architecture with an out of order execution engine in the middle. The Intel Architecture Optimization Manual lists the following two diagrams:
|
|
The two sections shown are essentially concatenated, showing 10 stages of in-order processing (since retirement must also be in-order) with 3 stages of out of order execution (RS, the Ports, and ROB write back colored in light blue by me, not Intel.)
Intel's basic idea was to break down the problem of execution into as many units as possible and to peel away every possible stall that was incurred by their previous Pentium architecture as each instructions marches forward down their assembly line. In particular, Intel invests 5 pipelined clocks to go from the instruction cache to a set of ready to execute micro-ops. (RISC architectures have no need for these 5 stages, since their fixed width instructions are generally already specified to make this translation immediate. It is these 5 stages that truly separate the x86 from ordinary RISC architectures, and Intel has essentially solved it with a brute force approach which costs them dearly in chip area.)
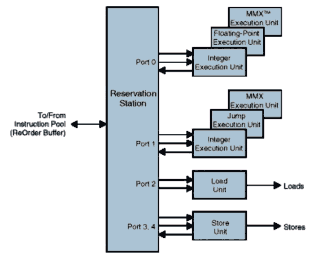
Each of Intel's "Ports" is used as a feeding trough for microops to various groupings of units as shown in the above diagram. So, Intel's 5 micro-op execution per clock bandwidth is a little misleading in the sense that two ports are required for any single storage operation. So, it is more realistic to consider this equivalent, to at most 4 K6 RISC86 ops issued per clock.
As a note of interest, Intel divides the execution and write back stages into two seperate stages (the K6 does not, and there is really no compelling reason for the P6's method that I can see.)
Although it is not as well described, I believe that Intel's reservation station and reorder buffer combinations serves substantially the same purpose as the K6's scheduler, and similarly the retire unit acts on instruction clusters in exactly the same way as they were issued (CPUs are not otherwise known to have sorting algorithms wired into them.) Thus the micro-op throughput is limited to 3 per clock (compared with 4 RISC86 ops for the K6.)
So when everything is working well, the P-II can take 3 simple x86 instructions and turn them into 3 micro-ops on every clock. But, as can be plainly seen in their comments, they have a bizzare problem: they can only read two physical input register operands per clock (rename registers are not constrained by this condition.) This means scheduling becomes very complicated. Registers to be read for multiple purposes will not cost very much, and data dependencies don't suffer from any more clocks than expected, however the very typical trick of spreading calculations over several registers (used especially in loop unrolling) will upper bound the pipeline to two micro-ops per clock because of a physical register read bottleneck.
In any event, the decoders (which can decode up to 6 micro-ops per clock) are clearly out-stripping the later pipeline stages which are bottlenecked both by the 3 micro-op issue and two physical register read operand limit. The front end easily outperforms the back end. This helps Intel deal with their branch bubble, by making sure the decode bandwidth can stay well ahead of the execution units.
Something that you cannot see in the pictures above is the fact that the FPU is actually divided into two partitioned units. One for addition and subtraction and the other for all the other operations. This is found in the Pentium Pro documentation and given the above diagram and the fact that this is not mentioned anywhere in the P-II documentation I assumed that in fact the P-II was different from the PPro in this respect (Intel's misleading documentation is really unhelpful on this point.) After I made some claims about these differences on USENET some Intel engineer (who must remain anonymous since he had a copyright statement insisting that I not copy anything he sent me -- and it made no mention of excluding his name) who claims to have worked on the PPro felt it his duty to point out that I was mistaken about this. In fact, he says, the PPro and P-II have an identical FPU architecture. So in fact the P-II and PPro really are the same core design with the exception of MMX, segment caching and probably some different glue logic for the local L2 caches.
This engineer also reiterated Intel's position on not revealing the inner works of their CPU architectures thus rendering it impossible for ordinary software engineers to know how to properly optimize for the P-II.
In order to do this in a sound manner, subsequent instructions must be executed "speculatively" under the proviso that any work done by them may have to be undone if the prediction turns out to be wrong. This is handled in part by renaming target write-back registers to shadow registers in a hidden set of extra registers. The K6 and 6x86MX have similar rename and speculation mechanisms, but with its longer latencies, it is a more important feature for the P-II. The trade off is that the process of undoing a mispredicted branch is slow (since the pipelines must completely flush) costing as much as 15 clocks (and no less than 11.) These clocks are non-overlappable with execution, of course, since the execution stream cannot be correctly known until the mispredict is completely processed. This huge penalty offsets the performance of the P-II, especially in code in which no P6/P-II optimizations considerations have been made.
The P-II's predictor always deals with addresses (rather than boolean compare results as is done in the K6) and so is applicable to all forms of control transfer such as direct and indirect jumps and calls. This is critical to the P-II given that the latency between the ALUs and the instruction fetch is so large.
In the event of a conditional branch both addresses are computed in parallel. But this just aids in making the prediction address ready sooner; there is no appreciable performance gained from having the mispredicted address ready early given the huge penalty. The addresses are computed in an integer execution port (seperate from the FPU) so branches are considered an ALU operation. The prefetch buffer is stalled for one clock until the target address is computed, however since the decode bandwidth out-performs the execution bandwidth by a fair margin, this is not an issue for non-trivial loops.
This all means that the average loop penalty is:
(90% * 0) + (10% * 13) = 1.3 clocks per loop
This is obviously a lot higher than the K6 penalty. (The zero as the first penalty assumes that the loop is sufficiently large to hide the one clock branch bubble.)
For programmers this means one major thing: Avoid mispredicted branches in your inner loops at all costs (make that 10% closer to 0%). Using tables or conditional move instructions are common methods, however since the predictor is used even in indirect jumps, there are situations with branching where you have no choice but to suffer from branch prediction penalties.
The Intel floating point design has traditionally beat the Cyrix and AMD CPUs on floating point performance and this still appears to hold true as tests with Quake and 3D Studio have confirmed. (The K6 is also beaten, but not by such a large margin -- and in the case of Quake II on a K6-2 the roles are reversed.)
The P-II's floating point unit is issued from the same port as one of the ALU units. This means that it cannot issue two integer and 1 floating point operation on every clock, and thus is likely to be constrained to an issue rate similar to the K6. As Andreas Kaiser points out, this does not necessarily preclude later execution clocks (for slower FPU operations for eg) to execute in parallel from all three basic math units (though this same comment applies to the K6).
As I mentioned above, the P-II's floating point unit is actually two units, one is a fully pipelined add and subtract unit, and the other is a partially pipelined complex unit (including multiplies.) In theory this gives greater parallelism opportunities over the original Pentium but since the single port 0 cannot feed the units at a rate greater than 1 instruction per clock, the only value is design simplification. For most code, especially P5 optimized code, the extra multiply latency is likely to be the most telling factor.
Update: Intel has introduced the P-!!! which is nothing more than a 500Mhz+ P6 core with 3DNow!-like SIMD instructions. These instructions appear to be very similar in functionality and remarkably similar in performance to the 3DNow! instruction set. There are a lot of misconceptions about the performance of SSE versus 3DNow! The best analysis I've seen so far indicate that they are nearly identical by virtue of the fact that Intel's "4-1-1" issue rate restriction holds back the mostly meaty 2 micro-op SSE instructions. Furthermore, there are twice as many subscribers to the SSE units per instruction than 3DNow! which totally nullifies the doubled output width. In any event, its almost humorous to see Intel playing catch up to AMD like this. The clear winner: consumers.
The greater associativity helps programs that are written indifferently with respect to data locality, but has no effect on code mindful of data locality (i.e., keeping their working sets contiguous and no larger than the L1 cache size.)
The P-II also has an "on PCB L2 cache". What this means is they do not need use the motherboard bus to access their L2 cache. As such the communications interface can (and does) have a much higher frequency. In current P-II's it is 1/2 the CPU clock rate. This is an advantage over K6, K6-2 and 6x86MX cpus which access motherboard based L2 caches at only 66Mhz or 100Mhz. (However the K6-III's on die L2 cache runs at the CPU clock rate, which is thus twice as fast as the P-II's)
As described by Agner Fog, the front end is in-order and must assign internal registers before the instruction can be entered into the reservations stations. If there is a partial register overlap with a live instruction ahead of it, then a disjoint register cannot be assigned until that instruction retires. This is a devastating performance stall when it occurs because new instructions cannot even be entered into the reservations stations until this stall is resolved. Intel lists this as having roughly a 7 clock cost.
Intel recommends using XOR reg,reg or SUB reg,reg which will somehow mark the partial register writes as automatically zero extending. But obviously this can be inappropriate if you need other parts of the register to be non-zero. It is not clear to me whether or not this extends to memory address forwarding (it probably does.) I would recommend simply seperating the partial register write from the dependent register read by as much distance as possible.
This is not a big issue so long as the execution units are kep busy with instructions leading up to this partial registers stall, but that is a difficult criteria to code towards. One way to accomplish this would be to try to schedule this partial register stall as far away from the previous branch control transfer as possible (the decoders usually get well ahead of the ALUs after several clocks following a control transfer.)
Only under these circumstances can the P-II achieve its maximum rate of decoding 3 instructions per cycle.
Update: I recently tried to hand optimize some code, and found that it is actually not all that difficult to achieve the 3 instruction issue per clock, but that certainly no compiler I know of is up to the task. It turns out, though, that such activities are almost certainly a red herring since dependency bubbles will end up throttling your performance anyways. My recommendation is to parallelize your calculations as much as possible.
At the same clock rate, this is its biggest advantages over the current K6 whose L2 cache is tied to the chipset speed of 66Mhz.
But now, after being pressured into publishing information about MSRs, Intel has decided to go one step further and provide a tool to help present the MSR information in a Windows program. While this tool is very useful in of itself, it would be infinitely superior if there were accompanying documentation that described the P-II's exact scheduling mechanism.
While they claim that hand scheduling has little or no effect on performance experiments I and others have conducted have convinced me that this simply is not the case. In the few attempts I've made using ideas I've recently been shown and studied myself, I can get between 5% and 30% improvement on very innocent looking loops via some very unintuitive modifications. The problem is that these ideas don't have any well described explanation -- yet.
With the P-II we find a nice dog and pony show, but again the documentation is inadequate to describe essential performance characteristics. They do steer you away from the big performance drains (branch misprediction and partial register stalls.) But in studying the P-II more closely, it is clear that there are lots of things going on under the hood that are not generally well understood. Here are some examples (1) since the front end out-performs the back-end (in most cases) the "schedule on tie" situation is extremely important, but there is not a word about it anywhere in their documentation (Lee Powell puts this succinctly by saying that the P-II prefers 3X superscalar code to 2X superscalar code.) (2) The partial register stall appears to, in some cases, totally parallelize with other execution in some cases (the stall is less than 7 clocks), while not at all in others (a 7 clock stall in addition to ordinary clock expenditures.) (3) Salting execution streams with bogus memory read instructions can improve performance (I strongly suspect this has something to do with (1)).
So why doesn't Intel tell us these things so we can optimize for their CPU? The theory that they are just telling Microsoft or other compiler vendors under NDA doesn't fly since the kinds of details that are missing are well beyond the capabilities of any conventional compiler to take advantage of (I can still beat the best compilers by hand without even knowing the optimization rules, but instead just by guessing at them!) I can only imagine that they are only divulging these rules to certain companies that perform performance critical tasks that Intel has a keen interest in seeing done well running on their CPUs (soft DVD from Zoran for example; I'd be surprised if Intel didn't give them either better optimization documentation or actual code to improve their performance.)
Intel has their own compiler that they have periodically advertised on the net as a plug in replacement for the Windows NT based version of MSVC++, available for evaluation purposes (it's called Proton if I recall correctly). However, it is unclear to me how good it is, or whether anyone is using it (I don't use WinNT, so I did not pursue trying to get on the beta list). Update: I have been told that Microsoft and Imprise (Borland) have licensed Intel's compiler source and has been using it are their compiler base.
Recommendations I know of: (1) Avoid mispredicted branches (using conditional move can be helpful in removing unpredictable branches), (2) Avoid partial register stalls (via the xor/sub reg,reg work arounds, or the movzx/movsx commands or by simply avoiding smaller registers.) (3) Remove artificial "schedule on tie" stalls by slowing down the front end x86 decoder (i.e., issuing a bogus bypassed load command by rereading out of the same address as the last memory read can often help.) For more information read the discussion on the sandpile.org discussion forum (4) Align branch target instructions; they are not fed to the second prefetch stage fast enough to automatically align in time.
During 1998, what consumers have been begging for for years, a transition to super cheap PCs has taken place. This is sometimes called the sub-$1000 PC market segment. Intel's P-II CPUs are simply too expensive (costing up to $800 alone) for manufacturers to build compelling sub-$1000 systems with them. As such, Intel has watched AMD and Cyrix pick up unprecedented market share.
Intel made a late foray into the sub-$1000 PC market. Their whole business model did not support such an idea. Intel's "value consumer line" the Celeron started out as a L2-cacheless piece of garbage architecture (read: about the same speed as P55Cs at the same clock rates), then switched to an integrated L2 cache architecture (stealing the K6-3's thunder). Intel was never really able to recover the bad reputation that stuck to the Celeron, but perhaps that was their intent all along. It is now clear that Intel is basically dumping Celerons in an effort to wipe out AMD and Cyrix, while trying to maintain their hefty margins in their Pentium-II line. For the record, there is little performance difference between a Pentium-II and a Celeron, and the clock rates for the Celeron were being made artificially slow so as not to eat into their Pentium line. This action alone has brought a resurgence into the "over clocking game" that some adventurous power users like to get into.
But Intel being Intel has managed to seriously dent what was exclusively an AMD and Cyrix market for a while. Nevertheless since the "value consumer" market has been growing so strongly, AMD and Cyrix have nevertheless been able to increase their volumes even with Intel's encroachment.
The P-II architecture is getting long in the tooth, but Intel keeps insisting on pushing it (demonstrating an uncooled 650Mhz sample in early 1999.) Mum's the word on Intel's seventh generation x86 architecture (the Williamette or Foster) probably because that architecture is not scheduled to be ready before late 2000. This old 6th generation part may prove to be easy pickings for Cyrix Jalapeno and AMD's K7, both of which will be available in the second half of 1999.
| The Cyrix 6x86MX |
The primary microarchitecture difference of the 6x86MX CPU versus the K6 and P-II CPUs is that it still does native x86 execution rather than translation to internal RISC ops.
By being able to swap the instructions, there is no concern about artificial stalls due to scheduling of instruction to the wrong pipeline. By introducing two address generation stages, they eliminate the all too common AGI stall that is seen in the Pentium. The 6x86MX relies entirely on up front dependency resolution via register renaming, and data forwarding; it does not buffer instructions in any way. Thus its instruction issue performance becomes bottlenecked by dependencies.
The out of order nature of the execution units are not very well described in Cyrix's documentation beyond saying that slower instructions will make way for faster instructions. Hence it is not clear what the execution model really looks like.
They have a fixed scheme of 4 levels of speculation, that are simply increased for every new speculative instruction issued (this is somewhat lower than the P-II and K6 which can have 20 or 24 live instructions at any one given time, and somewhat more outstanding branches.)
The 6x86MX architecture is more lock stepped than the K6, and as such their issue follows their latency timings more closely. Specifically their decode, issue and address generation stages are executed in lock step, with any stalls from resource contentions, complex decoding etc, backing up the entire instruction fetch stages. However their design makes it clear that they do everything possible to reduce these resource contentions as early as possible. This is to be contrasted with the K6 design which is not lock step at all, but due to its late resource contention resolution, may be in the situation of re-issuing instructions after potentially wasting an extra clock that it didn't need to in its operand fetch stage.
Like AMD, Cyrix designed their 6x86MX floating point around the weak code that x86 compilers generate on FPU code. But, personally, I think Cyrix has gone way too far in ignoring FPU performance. Compilers only need to get a tiny bit better for the difference between the Cyrix and Pentium II to be very noticeable on FPU code.
Thus the L1 cache becomes a sort of L2 cache for the 256 byte instruction line buffer, which allows the Cyrix design to complicate a much smaller cache structure with predecode bits and so on, and use the unified L1 cache more efficiently as described above. Although I don't know details, the prefetch units could try to see a cache miss comming and pre-load the instruction line cache in parallel with ordinary execution; this would compensate for the instruction cache's unusually small size, I would expect to the point of making it a mute point.
Although I have not read about the Cyrix in great detail, it would seem to me that this was motivated by the desire to perform well on multimedia algorithms. The reason is that multimedia tends to use memory in streams, instead of reusing data which conventional caching strategies are designed for. So if the Cyrix's cache line locking mechanism allows redirecting of certain memory loads then this will allow them to keep the rest of their L1 cache intact for use by tables or other temporary buffers. This would be a good strategy for their next generation MXi processor (an integrated graphics and x86 processor.)
It is my understanding that Cyrix commissioned Green Hills to create a compiler for them, however I have not encountered or even heard of any target code produced by it (that I know of). Perhaps the MediaGX drivers are built with it.
Update: I've been recently pointed at Cyrix's Appnotes page, in particular note 106 which describes optimization techniques for the 6x86 and 6x86MX. It does provide a lot of good suggestions which are in line with what I know about the Cyrix CPUs, but they do not explain everything about how the 6x86MX really works. In particular, I still don't know how their "out of order" mechanism works.
It is very much like Intel's documentation which just tells software developers what to do without giving complete explanations as to how their CPU works. The difference is that its much shorter and more to the point.
One thing that surprised me is that the 6x86MX appears to have several extended MMX instructions! So in fact, Cyrix had actually beaten AMD to (nontrivially) extending the x86 instruction set (with the K6-2), they just didn't do a song and dance about it at the time. I haven't studied them yet, but I suspect that when Cyrix releases their 3DNOW! implementation they should be able to advertise the fact that they will be supplying more total extensions to the x86 instruction set with all of them being MMX based.
Well, whatever it is, Cyrix learned an important lesson the hard way: clock rate is more important than architectural performance. Besides keeping Cyrix in the "PR" labelling game, their clock scalability could not keep up with either Intel or AMD. Cyrix did not simply give up however. Faced with a quickly dying architecture, a shared market with IBM, as well as an unsuccessful first foray into integrated CPUs, Cyrix did the only thing they could do -- drop IBM, get foundry capacity from National Semiconductor and sell the 6x86MX for rock bottom prices into the sub-$1000 PC market. Indeed here they remained out of reach of either Intel and AMD, though they were not exactly making much money with this strategy.
Cyrix's acquisition by National Semiconductor has kept their future processor designs funded, but Cayenne (a 6x86MX derivative with a faster FPU and 3DNow! support) has yet to appear. Whatever window of opportunity existed for it has almost surely disappeared if it cannot follow the clock rate curve of Intel and AMD. But the real design that we are all waiting for is Jalapeno. National Semiconducter is making an very credible effort to ramp up its 0.18 micron process and may beat both Intel and AMD to it. This will launch Jalapeno at speeds in excess of 600Mhz with the "PR" shackels removed, which should allow Cyrix to become a real player again.
Update: National has buckled under the pressure of keeping the Cyrix division alive (unable to produce CPUs with high enough clock rate) and has sold it off to VIA. How this affects Cyrix' ability to try to reenter the market, and release next generation products remains to be seen.
| Common Features |
Within the scheduler the order of the instructions are maintained. When a micro-op is ready to retire it becomes marked as such. The retire unit then waits for micro-op blocks that correspond to x86 instructions to become entirely ready for retirement and removes them from the scheduler simultaneously. (In fact, the K6 retains blocks corresponding to all the RISC86 ops scheduled per clock so that one or two x86 instructions might retire per clock. The Intel documentation is not as clear about its retirement strategies.) As instructions are retired the non-speculative CS:EIP is updated.
The speculation aspect is the fact that the branch target of a branch prediction is simply fed to the prefetch immediately before the branch is resolved. A "branch verify" instruction is then queued up in place of the branch instruction and if the verify instruction checks out then it is simply retired (with no outputs except possibly to MSRs) like any ordinary instruction, otherwise a branch misprediction exception occurs.
Whenever an exception occurs (including branch mispredicts, page fault, divide by zero, non-maskable interrupt, etc) the currently pending instructions have to be "undone" in a sense before the processor can handle the exception situation. One way to do this is to simply rename all the registers with the older values up until the last retirement which might be available in the current physical register file, then send the processor into a kind of "single step" mode.
According to Agner Fog, the P-II retains fixed architectural registers which are not renamable and only updated upon retiring. This would provide a convenient "undo" state. This also jells with the documentation which indicates that the PII can only read at most two architectural registers per clock. The K6, however, does not appear to be similarly stymied, however it too has fixed architectural registers as well.
The out of orderedness is limited to execution and register write-back. The benefits of this are mostly in mixing multiple instruction micro-op types so that they can execute in parallel. It is also useful for mixing multi-clock, or otherwise high-latency instructions with low-clock instructions. In the absence of these opportunities there are few advantages over previous generation CPU technologies that aren't taken care of by compilers or hand scheduling.
Contrary to what has been written about these processors, however, hand tuning of code is not unnecessary. In particular, the Intel processors still handle carry flag based computation very well, even though compilers do not; the K6 has load latencies, all of these processors still have alignment issues and the K6 and 6x86MX prefer the LOOP instruction which compilers do not generate. XCHG is also still the fastest way to swap two integer registers on all these processors, but compilers continue to avoid that instruction. Many of the exceptions (partial register stall, vector decoding, etc.) are also unknown to most modern compilers.
In the past, penalties for cache misses, instruction misalignment and other hidden side-effects were sort of ignored. This is because on older architectures, they hurt you no matter what, with no opportunity for instruction overlap, so the rule of avoiding them as much as possible was more important than knowing the precise penalty. With these architectures its important to know how much code can be parallelized with these cache misses. Issues such as PCI bus, chip set and memory performance will have to be more closely watched by programmers.
The K6's documentation was the clearest about its cache design, and indeed it does appear to have a lot of good features. Their predecode bits are used in a very logical manner (which appears to buy the same thing that the Cyrix's instruction buffer buys them) and they have stuck with the simple to implement 2-way set associativity. A per-cache line status is kept, allowing independent access to separate lines.
| Final words |
While these architectures are impressive, I don't believe that programmers can take such a relaxed attitude. There are still simple rules of coding that you have to watch out for (partial register stalls, 32 bit coding, for example) and there are other hardware limitations (at most 4 levels of speculation, a 4 deep FPU FIFO etc.) that still will require care on the part of the programmer in search of the highest levels of performance. I also hope that the argument that what these processors are doing is too complicated for programmers to model dies down as these processors are better understood.
Some programmers may mistakenly believe that the K6 and 6x86MX processors will fade away due to market dominance by Intel. I really don't think this is the case, as my sources tell me that AMD and Cyrix are selling every CPU they make, as fast as they can make them. The demand is definately there. 3Q97 PC purchases indicated an unusually strong sales for PCs at $1000 or less (dominated by Compaq machines powered by the Cyrix CPU), making up about 40% of the market.
The astute reader may notice that there are numerous features that I did not discuss at all. While its possible that it is an oversight, I have also intentionally left out discussion of features that are common to all these processors (data forwarding, register renaming, call-return prediction stacks, and out of order execution for example.) If you are pretty sure I am missing something that should be told, don't hesitate to send me feedback.
Update: Centaur, a subsidiary of IDT, has introduced a CPU called the WinChip C6. A brief reading of the documentation on their web site indicates that its basically a single pipe 486 with a 64K split cache dual MMX units, some 3D instruction extensions and generally more RISCified instructions. From a performance point of view their angle seems to be that the simplicity of the CPU will allow quick ramp up in clock rate. Their chip has been introduced at 225 and 240 MHz initially (available in Nov 97) with an intended ramp up to 266 and 300 Mhz by the second half of 1998. They are also targeting low power consumption, and small die size with an obvious eye towards the laptop market.
Unfortunately, even in the test chosen by them (WinStone; which is limited by memory, graphics and hard disk speed as much as CPU), they appear to score only marginally better than the now obsolete Pentium with MMX, and worse than all other CPUs at the same clock rate. These guys will have to pick their markets carefully and rely on good process technology to deliver the clock rates they are planning for.
Update: They have since announced the WinChip 2 which is superscalar and they expect to have far superior performance. (They claim that they will be able to clock them between 400 and 600 Mhz) We shall see; and we shall see if they explain their architecture to a greater depth.
Update: 05/29/98 RISE (a startup Technology Company), has announced that they too will introduce an x86 CPU, however are keeping a tight lid on their architecture.
| Glossary of terms |
| Links |



